A Shiny App for Exploratory Qualitative Analysis
This post is to share my (first) R Shiny app, which was produced as a result of a Qualitative analysis project I carried out for the Office of the Police and Crime Commissioner (OPCC), Norfolk, UK. The Shiny app provides users to either upload sample corpora made available with the app, or to simply upload custom corpora. It, then, enables users to
- Check word distributions from corpora
- Cluster documents and perform Topic modelling
- Cluster words and produce word clouds
- Generate networks of words
The following sections elaborate on the different aspects of this app.
Phase Selection & User Guide
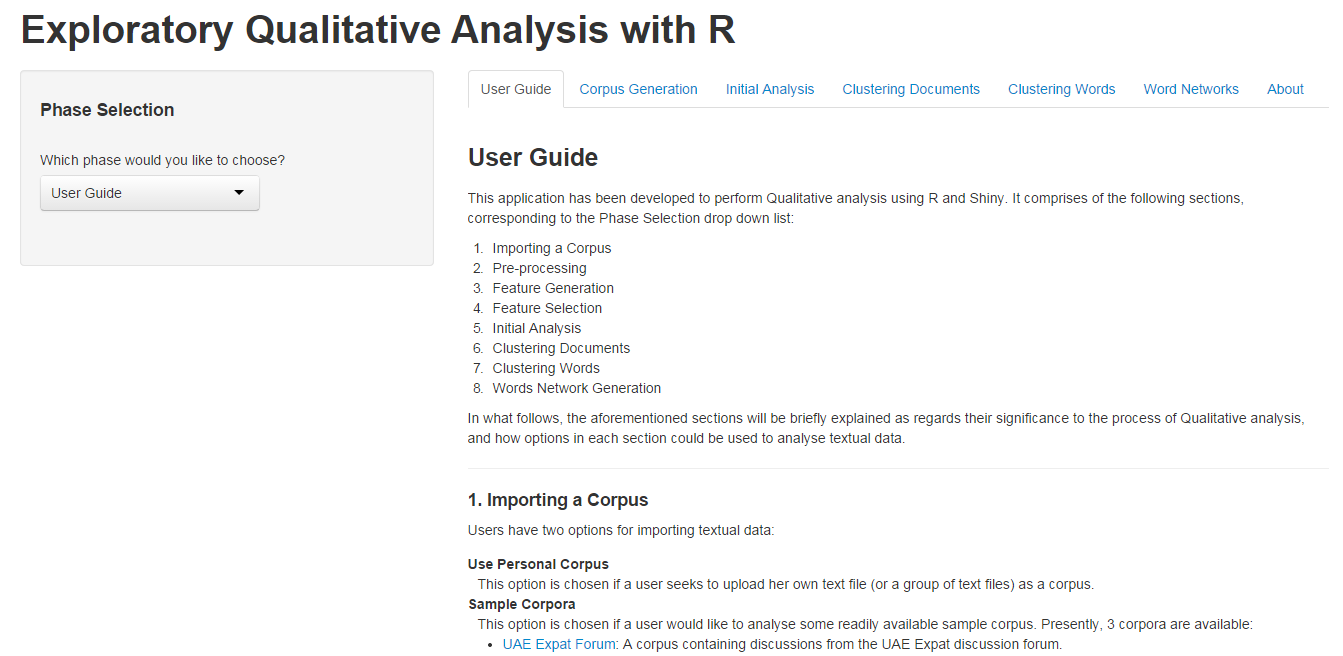
The Phase Selection drop down list enables users to select which phase they want to enter for Qualitative analysis. Although the tabs, being visible, may naturally prompt the user to select any phase by clicking at them, they are not actually meant for this purpose. The purpose of tabs is just to keep separated the different phases in the app, while the Phase Selection list is meant to facilitate users to select a phase of their choice.
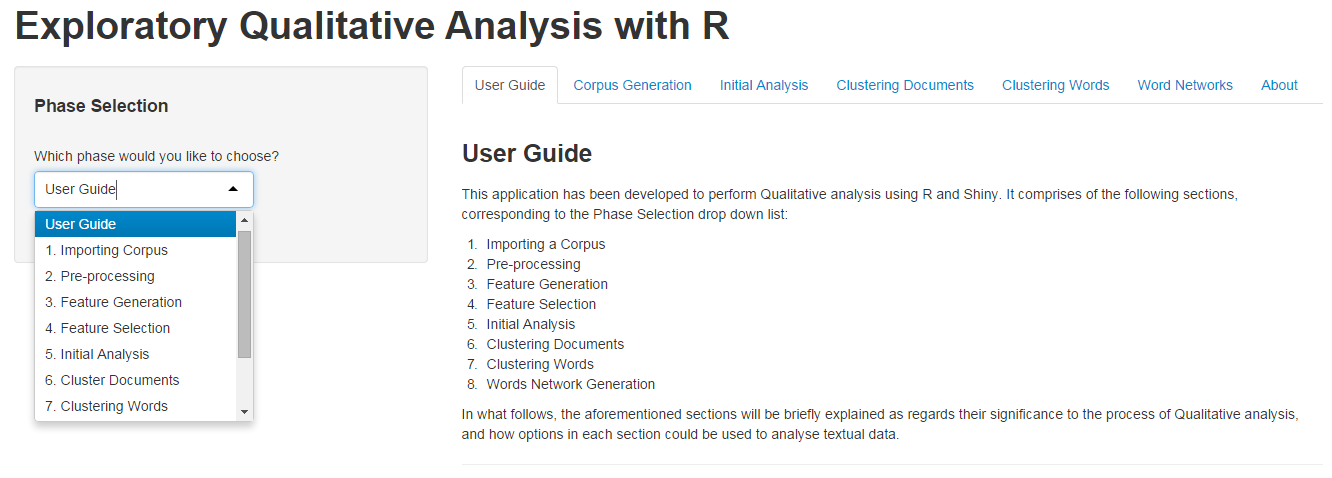
Importing a Corpus
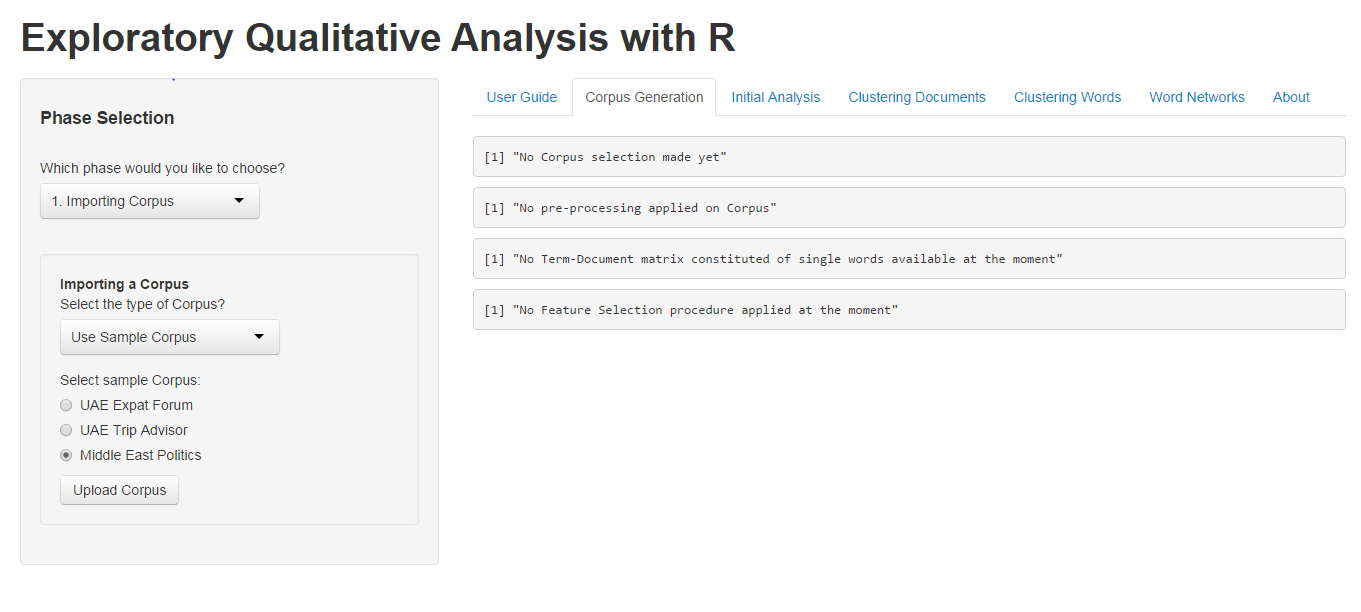
Users have the option of uploading either their custom corpus (which may be a single text file with a new line as a delimiter, or a collection of similar text files), or a sample corpus. Currently, three sample corpora are available for users:
- UAE Expat Forum
- UAE Trip Advisor
- Middle East Politics
These corpora were constructed after performing some web scrapping of discussion forums. The code for web scraping these websites can be found here. For the purpose of demonstration, we shall select the Middle East Politics data set.
After selection, clicking on the ‘Upload Corpus’ button uploads the selected corpus, with a message being displayed in the right panel.
Preprocessing
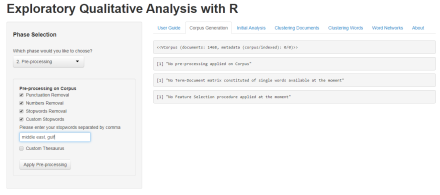
The Pre-processing phase enables users to perform several basic pre-processing procedures, such as removal of punctuation, numbers, and stopwords. This app also allows users to enter custom stopwords, separated by a comma, as well as custom thesauri, with the same procedure of separating words with commas.
The ‘Apply Pre-processing’ button applies the selected pre-processing procedures to our corpus data.
Feature Generation
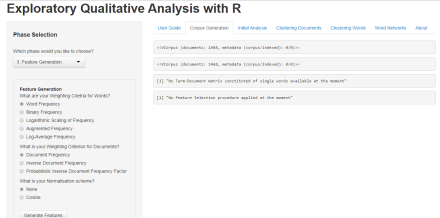
The Feature Generation phase is provided for users to select weighting criteria for words, documents, and a normalisation scheme. Once selected, the ‘Generate Features’ button applies the selected criteria to words and documents.
For this demonstration, I have chosen TF scheme, with no normalisation.
Feature Selection
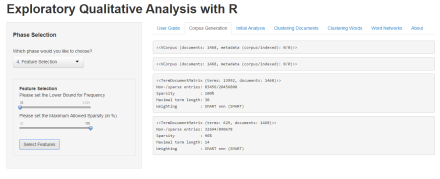
The Feature Selection phase is an integral part of the app (given how it enables us to cut down on memory being used – memory limitations apply to this app, of course). Users may determine a lower bound for word frequency, or set the allowed sparsity level. The ‘Select Features’ button calculates the new Term Document matrix. We shall set our frequency lower bound to 33, and leave the default value for sparsity level.
Initial Analysis
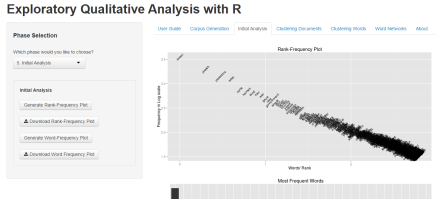
In the Initial Analysis phase, users have the options to plot a Rank Frequency plot, or a Word Frequency plot, both of which are downloadable as PDF files.
Cluster Documents
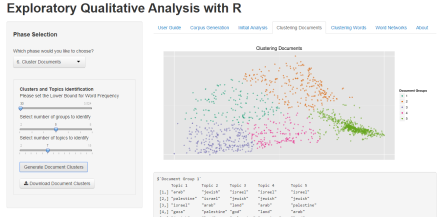
To Cluster documents, users have to select a lower bound for word frequency, the number of documents they want to identify in clustering procedure, as well as the number of topics they wish to identify from the clustered documents. The resulting graph is downloadable as a PDF file.
Cluster Words and Phrases
To Cluster words, users select the quantile for word frequency (which has the same purpose as of selecting a lower bound for word frequency), the number of groups they want to form for words, and finally one of the two force-drawing graph algorithms. This graph can also be downloaded as a PDF file.
In addition to the above, users may also create a dendrogram of words, from relevant options made available in the app.
Word Networks
This phase can be used to identify relations between words – the association of words to each other is represented by inter-connecting lines, just as in a network. To generate a network of words, users first select the quantile for word frequency, just as in the Word Clustering phase, and then simply select one of the two force-drawing graph algorithms. The ‘Generate Words Network’ button plots the graph, which can also be downloaded as a PDF file.
This phase is also the most memory-intensive phase. I realise that, at time, the plotted network may not be intelligible. Hope to improve it soon.
I would be very eager to hear any generous amount of criticism, or your thoughts in general, about this app.
Many thanks for your time reading through this post!